|
Frequently Asked Questions
- What is XLIFF?
- Why use XLIFF?
- What is the most recent version of XLIFF?
- Where can I find the latest XLIFF specification?
- What is "localisation"?
- What is the difference between "localisation" and "translation"?
- What questions should I ask an XLIFF tool vendor or translation service provider?
- How do I convert my localizable data into XLIFF content?
- Should <target> elements be prepopulated with a copy of the source when content is converted to XLIFF?
- How do I validate XLIFF documents?
- What does a typical localisation process look like?
- How can XLIFF be used to improve a typical localisation process?
- What sort of data is contained in an XLIFF document?
- How is data organized in an XLIFF document?
- How many languages can I put in an XLIFF document?
- Can I use my own element and/or attributes in XLIFF?
- Can I use my own attribute values in XLIFF?
- What is the difference between the id and resname attributes?
- What is the recommended extension for XLIFF documents?
- What is the difference between XLIFF and TMX?
- How do I translate an XLIFF document?
- What should be the content of <trans-unit> or <bin-unit> after translation has finished?
- What criteria should be used for choosing between the different approaches for representing inline formatting?
- Where can I find examples of XLIFF documents?
1. What is XLIFF?
XLIFF is a specification for the loss-less interchange of localizable data and its
related information. It is tool-neutral, has been formalized as an XML vocabulary
(through XML schema), and features an extensibility mechanism.
A white-paper describing how to use XLIFF is available for download at the following
URL:
http://www.oasis-open.org/committees/download.php/26817/xliff-core-whitepaper-1.2-cs.pdf
2. Why use XLIFF?
XLIFF addresses the following localisation challenges:
- Insufficient interoperability between tools.
- Lack of support for overall localisation workflow.
- Necessity of localisation tools developers to deal with many formats.
- Large number of proprietary intermediate formats.
XLIFF offers customers of localisation services the following advantages:
- Single format for adjunct processing (e.g. quality control in terms of spell checking).
- Less dependency on vendors which are able to work with special formats.
- Tighter control on what goes to localisation (Pre-filtering of what to translate or not).
- Controlled information flow (author/developer notes, item properties, etc.).
- Identifier-based leveraging.
- All advantages of XML-based processing.
XLIFF offers localisation tools vendors the following advantages:
- Focus on development of core functionality rather treatment of source format.
- Allow usage of tools in new contexts.
- All advantages of XML-based processing.
XLIFF offers localisation services providers the following advantages:
- Single format for adjunct processing (e.g. quality control in terms of spell checking).
- Less dependency on specific localisation tools.
- Controlled information flow (author/developer notes, item properties, etc.).
- Allow usage of tools in new contexts.
- All advantages of XML-based processing.
- Open and standard solution for proprietary formats.
3. What is the most recent version of XLIFF?
The most recent version of XLIFF is version 1.2, and was approved as an OASIS Committee Specification 02 in July 2007.
4. Where can I find the latest XLIFF specification?
The latest specification for XLIFF can always be found at:
http://docs.oasis-open.org/xliff/xliff-core/xliff-core.html
5. What is "localisation"?
LISA, the Localisation Industry Standards Association, defines Localisation as follows:
"Localisation involves taking a product and making it linguistically and culturally appropriate
to the target locale (country/region and language) where it will be used and sold."
For more information on localisation and related topics see:
6. What is the difference between "localisation" and "translation"?
Translation is the act of rendering text into another language.
Localisation is a special kind of translation that takes into account
the culture of the location or region where the translated text is expected to be
used.
For example, although English is spoken in both the United Kingdom and the USA,
differences in wording exist on either side of the Atlantic Ocean. Take for example
the UK spelling of "localisation", which is "localization" in the USA.
7. What questions should I ask an XLIFF tool vendor or translation service provider?
Prepare a check list of items to consider when selecting the tool to use for working
with XLIFF files. This list can include, for example:
- Version(s) of XLIFF supported
- Limitations in the size of the XLIFF file
- Support for translation memory (TM) matches stored in <alt-trans> elements
- Support for translating binary elements (<bin-unit>)
- Support for custom elements and attributes in custom namespaces
- Support for complex languages (e.g., Arabic, Hebrew, Chinese, Japanese, Korean, etc.)
Computer-aided translation (CAT) tool vendors usually provide evaluation versions
so that you can test the suitability of the tool for your situation.
8. How do I convert my localizable data into XLIFF content?
XLIFF is based on the concept of extracting the source localisation-related data
from the original format, and merging it back in place after the localisation has
been done. Extraction and merge routines must be developed for each native data
type as file filters, or XSL scripts.
Some open source and commercially available tools provide built-in support for the
more common resource types, so ask your tools vendor what resource types they support.
Extraction/Merge principle:
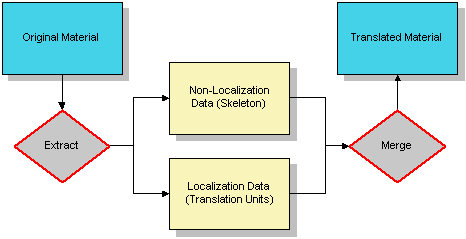
The parts that are not related to localisation are preserved temporarily into the
"Skeleton". There are no rules on how to represent the data in the Skeleton itself,
this is left to the discretion of the filters. XLIFF 1.1 focuses on how to store
and organize the extracted parts.
Skeletons can be either embedded directly in the XLIFF document with the <internal-file>
element or simply referred to with the <external-file> element.
For more information, see http://www-128.ibm.com/developerworks/xml/library/x-localis2/
9. Should <target> elements be prepopulated with a copy of the source when content is converted to XLIFF?
The <target> element is optional and should not contain
a copy of the source text when the XLIFF file is initially created
during the extraction step. Most tool vendors will provide a feature to
the translator to copy the source during the translation process.
Although it is valid to copy the source text in the <target>,
it makes the file unnecessarily larger. Some translation tools,
however, may work with XLIFF as generic XML and require the presence of
the <target> element, so check with your tool vendor.
10. How do I validate XLIFF documents?
XLIFF is specified in two "flavors". Indicate which of these variants you are using
by selecting the appropriate schema. The schema may be specified in the XLIFF document
itself or in an OASIS catalog. The namespace is the same for both variants. Thus,
if you want to validate the document, the tool used knows which variant you are
using. Each variant has its own schema that defines which elements and attributes
are allowed in certain circumstances.
As newer versions of XLIFF are approved, sometimes changes are made that render
some elements, attributes or constructs in older versions obsolete. Obsolete items
are deprecated and should not be used even though they are allowed. The XLIFF specification
details which items are deprecated and what new constructs to use.
- Transitional - Applications that produce older versions of XLIFF
may still use deprecated items. Use this variant to validate XLIFF documents that
you read. Deprecated elements and attributes are allowed.
xsi:schemaLocation='urn:oasis:names:tc:xliff:document:1.2 xliff-core-1.2-transitional.xsd'
- Strict - All deprecated elements and attributes are not allowed.
Obsolete items from previous versions of XLIFF are deprecated and should not be
used when writing new XLIFF documents. Use this to validate XLIFF documents that
you create.
xsi:schemaLocation='urn:oasis:names:tc:xliff:document:1.2 xliff-core-1.2-strict.xsd'
You can validate XLIFF documents using one of the W3C XML Schema (XSD) provided for this.
The XLIFF schema files are available at XLIFF Schemas.
11. What does a typical localisation process look like?
The translatable content ("resources") of an application, database or website is
first extracted, translated or modified for a given language or market and finally
rebuilt or redeployed. Numerous commercial tools are available to optimise and reduce
the cost of translation.
This use case describes a very primitive localisation process. In this example,
a developer writes code, and hands it off to a localisation engineer. All of the
process complexity exists in the localisation domain. The localisation engineer
receives all of the resources in their original native format. In order for the
native files to be localised, tool filters must be available that interpret the
localizable resources in the native file, or possibly complicated multi-tool solutions
are required in order to translate all the native files.
Typical localisation workflow without XLIFF:
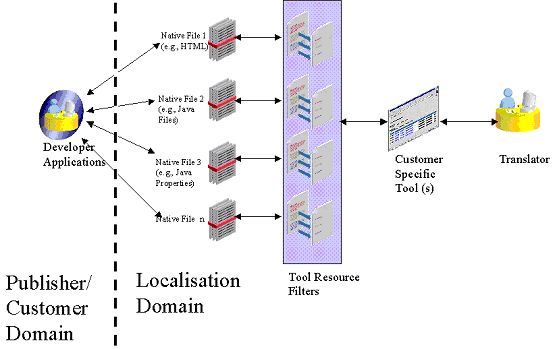
Each time a new native format is introduced or when an existing one is changed,
localisation tools engineers who may not be experts in the native format must revise
the tool and/or filter. And since new or changed resource types are generally discovered
when the tools fail during the midst of a project, supporting internal localisation
tools is a fire fight.
This model is highly reactive, and will inevitably result in project delays and
costs due to frequent retooling. It is also more likely introduce potential poor
quality of translated work due to misinterpreting data when converting between native
format and the localisation tool's internal data representation.
12. How can XLIFF be used to improve a typical localisation process?
Below is a use case that illustrates how XLIFF can be used to improve the localization process:
Localisation workflow with XLIFF:
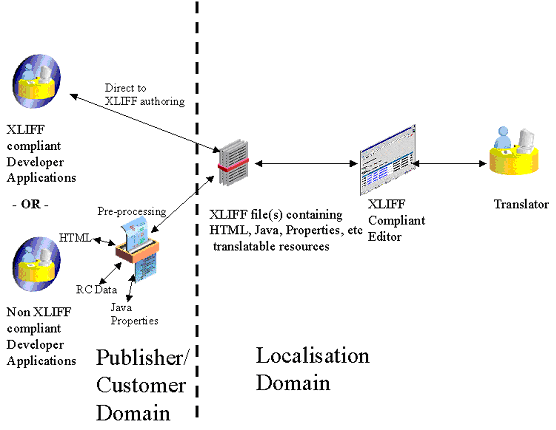
In this model, an XLIFF compliant tool outputs directly to XLIFF and this file is
handed off to the localisation engineers. Another scenario may be that developers
output their work to native files as before, but before the files are handed off
for localisation a pre-processor converts the data into XLIFF. In each of these
use cases, when new formats are introduced into the development process or existing
ones are changed, developer/publishers are responsible for handing off the data
as XLIFF.
This proactive model simplifies the formats that localisation tools must support,
and removes process complexity in the localisation engineering domain. It also places
the responsibility for converting the native data to XLIFF with those who are most
knowledgeable about the native format.
A more advance implementation is illustrated below.
Automated workflow with XLIFF and CAT tools:
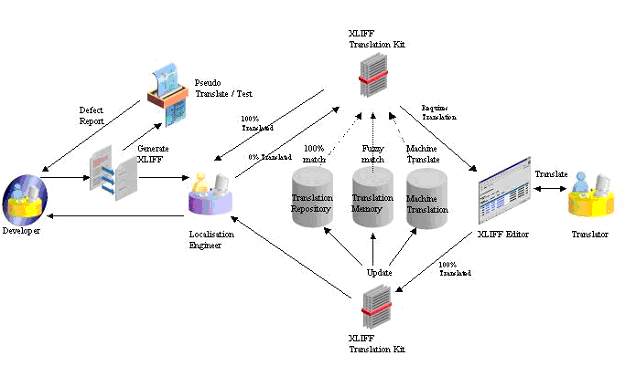
This use case further extends the workflow to include CAT (Computer Aided Translation)
tools. In this scenario, the XLIFF files are moved through the workflow as before,
but additionally translation memory fuzzy matches may be added to the XLIFF file
as <alt-trans>, and additionally machine translations may also
be added. XLIFF tools that support <alt-trans> may present to
the translator these "alternative translations" to enhance their productivity. Additionally,
reference to related glossary data can be stored in the XLIFF file and handed off
to the translator.
13. What sort of data is contained in an XLIFF document?
An XLIFF document contains essentially data that need to be modified in order to
localise the original resources from which the document is created. For example:
- Translatable text
- Coordinates of UI controls
- Font information
- etc.
It can also contain metadata (information about the data) such as:
- Identifier
- Maximum text length
- Type of resource
- Notes for the translators or the engineers
- etc.
14. How is data organized in an XLIFF document?
An XLIFF document is composed of one <file> element or more.
Each <file> element corresponds to an original data source, for
example a properties file, a database table, a graphic file, an HTML document, etc.
A <file> element is composed of a optional <header>
and a body <body>. The header is used to store file-level information,
the body contains the data to localise.
The translatable data are stored in <trans-unit> elements, which
can be organised in any levels of <group> elements. Binary data
can also be stored in the file, in <bin-unit> elements.
Example of XLIFF document:
<xliff version='1.2'
xmlns="urn:oasis:names:tc:xliff:document:1.2">
<file original="file1.prop" source-language="en-US"
datatype="javapropertyresourcebundle">
<header>
<skl><external-file href="file1.prop"/></skl>
</header>
<body>
<trans-unit id="1" resname="id1">
<source xml:lang="en-US">Text of string 1.</source>
</trans-unit>
<trans-unit id="2" resname="id2">
<source xml:lang="en-US">Text of string 2.</source>
</trans-unit>
</body>
</file>
<file original="file2.prop" source-language="en-US"
datatype="javapropertyresourcebundle">
<header>
<skl><external-file href="file2.prop"/></skl>
</header>
<body>
<trans-unit id="1" resname="id1bis">
<source xml:lang="en-US">String 1 file 2.</source>
</trans-unit>
<trans-unit id="2" resname="id2bis">
<source xml:lang="en-US">String 2 file 2.</source>
</trans-unit>
</body>
</file>
</xliff>
See more examples of XLIFF documents below.
15. How many languages can I put in an XLIFF document?
An XLIFF document is normally a bilingual file. It has one source language (the
language of the original extracted file), and one target language.
However, the <alt-trans> elements can be in language other than
the source or target one. This is to allow the document to carry translation candidates
(and their own source text) in multiple languages as the example shows below:
<trans-unit id='1'>
<source xml:lang='fr-fr'>Nouvelle couleur</source>
<alt-trans match-quality='100%'>
<source xml:lang='fr-ca'>Nouvelle couleur</source>
<target xml:lang='en-us'>New color</target>
</alt-trans>
<alt-trans match-quality='100%'>
<source xml:lang='fr-cm'>Nouvelle couleur</source>
<target xml:lang='en-au'>New colour</target>
</alt-trans>
</trans-unit>
In addition, since source and target language are defined at the <file>
element level, and an XLIFF document can contain several <file>
elements, it is technically possible to have an XLIFF document with more than one
source and one target language.
16. Can I use my own element and/or attributes in XLIFF?
Yes, it is possible to have user-defined elements and/or attributes in a valid XLIFF
document. You can do this by using the XML namespace mechanism.
The following elements allow non-XLIFF elements: <header>,
<group>, <tool>, <trans-unit>,
<alt-trans>, and <bin-unit>.
The following elements allow non-XLIFF attributes: <file>,
<group>, <trans-unit>, <source>,
<target>, <tool>, <bin-unit>,
<bin-source>, <bin-target>, <alt-trans>,
<mrk>, <g>, <x/>, <bx/>,
<ex/>, <bpt>, <ept>,
<ph>, and <it>.
Example of an XLIFF document with a private namespace (in bold):
<xliff version='1.2'
xmlns='urn:oasis:names:tc:xliff:document:1.2'
xmlns:xyz='www.mycompany.com/xyzext.1.2'>
<file original='Project.grf' source-language='en'
datatype='plaintext' xyz:srcroot='C:\Projects\Fiji\Images\en' xyz:autolink='yes' xyz:work='Thumbnails'>
<trans-unit id='jpemphasis.gif' xyz:screenshot='no'>
<source xml:lang='en'>Emphasis marks</source>
</trans-unit>
<trans-unit id='btnHome.png' xyz:screenshot='no'>
<source xml:lang='en'>Home</source>
</trans-unit>
<trans-unit id='btnSearch.png' xyz:screenshot='no'>
<source xml:lang='en'>Search</source>
</trans-unit>
</file>
</xliff>
See the section "Extensibility" in the specification for more information and examples.
17. Can I use my own attribute values in XLIFF?
Yes, it is possible to have user-defined attribute values in the following attributes:
context-type, count-type, ctype, datatype,
mtype, restype, size-unit, state,
state-qualifier, unit, priority, and purpose.
User-defined values must start with an "x-" prefix.
Example of an XLIFF document with user-defined values (in bold):
<xliff version='1.2'
xmlns='urn:oasis:names:tc:xliff:document:1.2'>
<file original='mydata.slk' source-language='en'
datatype='x-excel-slk'>
<trans-unit id='1:1' restype='x-const'>
<source xml:lang='en'>Root =</source>
</trans-unit>
<trans-unit id='1:1' restype='x-const'>
<source xml:lang='en'>Number of files =</source>
</trans-unit>
</file>
</xliff>
See the section "Extensibility" in the specification for more information and examples.
18. What is the difference between the id and resname attributes?
The id attribute is used to link a <trans-unit>
or an inline element to its original location in the source file from which the
XLIFF document was produced. The id attribute values are determined
by the tool that created the extracted document, they may or may not be the same
as the values of the resname attribute.
The resname attribute holds the original identifier of the text item
extracted in the <trans-unit> element. For example, with this
small properties file:
mnuItemFile=File mnnItemFileOpen=Open...
Some tools may use their own mechanism to link extracted data and the original file:
<trans-unit id='1' resname='mnuItemFile'>
<source>File</source>
</trans-unit>
<trans-unit id='2' resname='mnuItemFileOpen'>
<source>Open</source>
</trans-unit>
and some others may choose to use the property key:
<trans-unit id='mnuItemFile' resname='mnuItemFile'>
<source>File</source>
</trans-unit>
<trans-unit id='mnuItemFileOpen' resname='mnuItemFileOpen'>
<source>Open</source>
</trans-unit>
19. What is the recommended extension for XLIFF documents?
The recommended file extension for XLIFF documents is ".xlf".
20. What is the difference between XLIFF and TMX?
TMX (Translation Memory eXchange format) is a standard to exchange translation memory
content between tools. A collection of <tu> elements in TMX has
no specific order and contains no mechanism to rebuild the original file.
Both formats have some elements in common, especially regarding the inline mark-up
elements, but they are variations in the attributes of those elements. TMX uses
only the encapsulation methods for inline codes (there native codes are enclosed
within different elements), while XLIFF provides both the encapsulation method (using
elements very similar to TMX's) and the placeholder method (where the native codes
are removed to the Skeleton file and replaced by a short element that refers to
them, using elements very similar to OpenTag's). TMX allows any number of languages
in the same document. XLIFF is designed to work with one source and one target language.
TMX can be used in the same framework as XLIFF, for example to carry a translation
memory along with the data to localise.
21. How do I translate an XLIFF document?
There are different ways to translate an XLIFF documents:
With XLIFF-aware translation tools
Such tools have support to read XLIFF document and take advantage of all or most
XLIFF features, such as the pre-translated strings available in <alt-trans>
elements, and so forth.
Such tools do not require any specific pre-processing of the XLIFF document.
With XML-enable translation tools
Any translation that supports XML can be used to translate an XLIFF file. However,
depending on the capabilities of the tool, you may have to ensure a few things in
the XLIFF document.
In XLIFF the source text is in the <source> element, and the
translated text must go in the <target> element. Many XML-enable
tools cannot place the translation of a text in an element different from where
the source was taken, therefore you want to make sure the XLIFF document has a
<target> element with the original text to translate in each translation
unit.
In XLIFF translation units can be marked as "no to be translated", as in the example
below:
<trans-unit translate="no">
<source xml:lang='en'>Non-translatable text</source>
<target xml:lang='mn'>Non-translatable text</target>
</trans-unit>
Many XML-enabled tools cannot specify that a text is to be translated or not based
on a condition, but rely only on element and attribute names. To work around this
limitation, you must add a temporary element to allow the tool to detect the parts
that should be protected. In the example below, a temporary element <NTBT>
(not to be translated) has been added to enclose the protected text:
<trans-unit translate="no">
<source xml:lang='en'>Non-translatable text</source>
<target xml:lang='mn'><NTBT>Non-translatable text</NTBT></target>
</trans-unit>
Such pre-processing can be done very easily by applying the following XSL template
to the XLIFF document:
<?xml version="1.0" ?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:output encoding="utf-8" />
<xsl:template match="node()|@*">
<xsl:copy>
<xsl:apply-templates select="node()|@*"/>
</xsl:copy>
</xsl:template>
<xsl:template match="//trans-unit[@translate='no']/target">
<xsl:copy>
<xsl:apply-templates select="@*"/>
<NTBT><xsl:apply-templates/></NTBT>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
You must also make sure to remove any temporary elements you have added in the XLIFF
document before it comes back to the tool that will generate the final localised
file.
22. What should be the content of <trans-unit> or <bin-unit> after translation has finished?
After translation, all <trans-unit> or <bin-unit> elements
that do not have the "translate" attribute set to "no" contain a <target> element filled with
suitable target language content/translation for the content/text and markup inside the
corresponding <source> element. It is recommended to have the "approved" attribute set to "yes".
No tool may delete or modify content or meta-data in <source>. When segmenting
<source>, the segmented content should be cloned to a separate container, so
the original segment remains unaltered.
Having the unaltered <source> and the <target> available has
the following advantages:
- It is possible to perform post-translation operations like updating a translation memory, translation repository or to perform alignment operations. Aside: It is easy to turn XLIFF into TMX (Translation Memory eXchange), the standard format for translation memories.
- It is possible to support translation quality assurance/control activities (e.g. by sending out XLIFF to reviewers).
- It is possible to revert a
<trans-unit> to a non terminal state (such as the ones indicated by a "state" attribute value like "needs-translation", or "needs-review-translation").
23. What criteria should be used for choosing between the different approaches for representing inline formatting?
XLIFF has two mechanisms to representing inline formatting of the original:
- Abstraction: original inline markup is mapped to generic placeholder tags (
<g> and <x>)
- Encapsulation: original inline markup is encapsulated in typed placeholder tags (
<bpt>, <ept>, <ph> and <it>)
Thus, a snippet of RTF source content with bold as inline formatting like
This is \b bold\b0.
Could be represented in XLIFF in two ways:
- Via Abstraction
<trans-unit id="1">
<source>This is <g id="1" ctype="bold">bold</g>.</source>
</trans-unit>
- Via Encapsulation
<trans-unit id="1">
<source>This is <bpt id="1" ctype="bold">\b</bpt>bold<ept id="1">\b0</ept>.</source>
</trans-unit>
The example already indicates two major differences between the approaches:
- Abstraction provides maximum leveraging of translation memory data across incompatible resource types
RTF content like
This is \b bold\b0. can be represented in the same way as HTML content like
This is <b> bold</b>. Thus, if you work with a translation memory and have
already translated the RTF, you will get a good match when translating the HTML.
- Abstraction generates the need to have or store information about the original format.
Without this information, it will not be possible restore This is
<g id="1" ctype="bold">bold</g>. into RTF or HTML.
These differences provide some hints when to choose one approach over the other. Other aspects which may
need to be considered are listed below.
Some of these aspects pertain to the choice between abstraction and encapsulation wherease others pertain
to details within one of these approaches. Examples: When to use <ph> rather than
<ept>/<bpt>.
There is no magic recipe, the overall setting needs to be probed before making the choice.
Export to TMX
If you want the end user to export XLIFF files as TMX, then <g> and <x>
are bad choices. TMX 1.4 does not support <g> and <x> tags and it is
necessary to convert them to something else when exporting. Caveat: This might not be an issue anymore
with TMX 2.0.
As the original markup is in the skeleton, it may be impossible to include the markup in the generated TMX file.
Splitting Segments
If you use <bpt>/<ept> pairs and the translator wants to split the
segment, separating the tags, there are problems because it is required that each <bpt>
has an <ept> in the same <source> or <target>.
With two <ph> elements, you can separate them without problems in most cases.
If you use <g>, it would be necessary to clone the <g> tag in the
second segment and this is nasty. If you already cloned <g> element and the translator
merges two segments, you end with duplicated <g> tags. This doesn't happen if you
use <ph> instead.
Source Format
There are formats that don't require a skeleton, like Java Properties. In this case it is better to work
with <bpt>/<ept>, <ph> and <it>.
For some formats, so-called XLIFF profiles (ie. representation recommendations) have already been defined.
Accordingly, you should consult the existing profiles to see if a case like your's already has been covered.
Processing Environment
<g> and <x> are appealing because it ensures that format information
will not be spread across <trans-unit> elements.
With <bpt>/<ept> this is not the case. In the example below,
the format begin and format end are not within one single trans-unit. This may cause trouble when the
original format need to be reconstructed. This holds true for example in environments which use XSLT-based
processing since challenging recursive program calls would be needed.
<trans-unit id="%%%2%%%">
<source>Text 2 begins <bpt id="2" ctype="x-code" />code starts here.</source>
</trans-unit>
<trans-unit id="%%%3%%%">
<source>And code ends here.<ept id="2" ctype="x-code" />Now comes next TEXT.</source>
</trans-unit>
24. Where can I find examples of XLIFF documents?
Links to the latest official examples are available at XLIFF Examples.
Representation guides included at XLIFF Examples contain additional examples.
Last update: 14 January 2008
|