
OASIS DocBook Technical Committee
Working Draft 19 Mar 2002
- This version:
- Working Draft: 19 Mar 2002
- Previous versions:
- Working Draft: 19 Nov 2001
- Editor:
- Norman Walsh <Norman.Walsh@Sun.COM>
Copyright © 2001, 2002 The Organization for the Advancement of Structured Information Standards [OASIS]. All Rights Reserved.
This document and translations of it may be copied and furnished to others, and derivative works that comment on or otherwise explain it or assist in its implementation may be prepared, copied, published and distributed, in whole or in part, without restriction of any kind, provided that the above copyright notice and this paragraph are included on all such copies and derivative works. However, this document itself may not be modified in any way, such as by removing the copyright notice or references to OASIS, except as needed for the purpose of developing OASIS specifications, in which case the procedures for copyrights defined in the OASIS Intellectual Property Rights document must be followed, or as required to translate it into languages other than English.
The limited permissions granted above are perpetual and will not be revoked by OASIS or its successors or assigns.
This document and the information contained herein is provided on an "AS IS" basis and OASIS DISCLAIMS ALL WARRANTIES, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO ANY WARRANTY THAT THE USE OF THE INFORMATION HEREIN WILL NOT INFRINGE ANY RIGHTS OR ANY IMPLIED WARRANTIES OF MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE.
Abstract
This Standard defines XML encodings of the 19 standard character entity sets defined in Non-normative Annex D of [ISO 8879:1986].
Status of this Document
This Working Draft was approved for publication by the OASIS DocBook Technical Committee. Comments on this document may be sent to docbook@lists.oasis-open.org.
Table of Contents
Appendixes
- A. Added Latin 1
- B. Added Latin 2
- C. Greek Letters
- D. Monotoniko Greek
- E. Russian Cyrillic
- F. Non-Russian Cyrillic
- G. Numeric and Special Graphic
- H. Diacritical Marks
- I. Publishing
- J. Box and Line Drawing
- K. General Technical
- L. Greek Symbols
- M. Alternative Greek Symbols
- N. Added Math Symbols: Ordinary
- O. Added Math Symbols: Binary Operators
- P. Added Math Symbols: Relations
- Q. Added Math Symbols: Negated Relations
- R. Added Math Symbols: Arrow Relations
- S. Added Math Symbols: Delimiters
- T. Unicode Glyphs
- U. OASIS DocBook Technical Committee (Non-Normative)
- References
This Standard defines XML encodings of the standard SGML character entity sets.
Non-normative Annex D of [ISO 8879:1986] defines 19 standard SGML character entity sets: Added Latin 1, Added Latin 2, Greek Letters, Monotoniko Greek, Russian Cyrillic, Non-Russian Cyrillic, Numeric and Special Graphic, Diacritical Marks, Publishing, Box and Line Drawing, General Technical, Greek Symbols, Alternative Greek Symbols, Added Math Symbols: Ordinary, Added Math Symbols: Binary Operators, Added Math Symbols: Relations, Added Math Symbols: Negated Relations, Added Math Symbols: Arrow Relations, Added Math Symbols: Delimiters. The SGML declarations for these entities use the specific character data (SDATA) entity type that is not supported in XML, so alternative XML declarations are necessary.
In XML, the specific character data of most entities can be expressed as a [Unicode] character.
The character entity sets defined by this Standard are summarized in Appendix A through Appendix S.
In order to use these entities in a document, they must be declared. Entities can be declared in the external subset or the internal subset, as described in [XML 1.0]. An example document, with the declaration in the internal subset, is shown in Example 1.
Example 1. Declaring and Using the ISO Latin 1 Character Entity Set
<!DOCTYPE doc [
<!ENTITY % iso-lat1 PUBLIC "ISO 8879:1986//ENTITIES Added Latin 1//EN//XML"
"http://www.oasis-open.org/docbook/xmlcharent/0.2/isolat1.ent">
%iso-lat1;
]>
<doc>
<p>This document declares the ISO Latin 1 Character Entity Set, providing
access to the ISO Latin 1 entities, such as "é" and "©".</p>
</doc>Note
Non-validating XML Parsers may choose not to process externally declared entities. This Standard does not alter the semantics of XML processors. If a processor does not see the declaration for an entity, it will not be able to report the correct replacement text for that entity.
The replacement text of some entities includes more than a single Unicode character. Some characters are composed with the "combining reverse solidus overlay" (20E5) and some are composed with a variation selector (FE00, FE01, …).
Historically, the inodot entity is multiply defined in iso-lat2.ent and iso-amso.ent. If both entity sets are included, some parsers will warn about redefinition of this entity. The warning can be ignored.
There are a small number of entities that have no [Unicode] representation. These entities are all mapped to the Unicode character "FFFD", the "replacement character".
| Entity Name | Entity Set | Description |
|---|---|---|
| fjlig | iso-pub.ent | Small fj ligature |
| gnap | iso-amsn.ent | Greater, not approximate |
| jnodot | iso-amso.ent | Small j, no dot |
| lnap | iso-amsn.ent | Less, not approximate |
| lpargt | iso-amsc.ent | Greater than, left arc |
| nsmid | iso-amsn.ent | Negated short mid |
| prnE | iso-amsn.ent | Precedes, not double equals |
| rpargt | iso-amsc.ent | Right paren, greater than |
| scnE | iso-amsn.ent | Succeeds, not double equals |
| smid | iso-amsr.ent | shortmid r |
| vsubnE | iso-amsn.ent | Subset not double equals, variant |
Users needing these characters will have to rely on the private use area or other non-portable mechanisms to access them.
There are a few more for which there is no specific [Unicode] representation but where a reasonable substitution has been used:
| Entity Name | Entity Set | Substitution | Description |
|---|---|---|---|
| bepsi | iso-amsr.ent | 220D | Back epsilon: such that |
| ges | iso-amsr.ent | 2265 | Greater-or-equal, slanted |
| gvnE | iso-amsn.ent | 2269 | Gt, vert, not double equals |
| iff | iso-tech.ent | 21D4 | If and only if |
| les | iso-amsr.ent | 2264 | Less-than-or-equal, slanted |
| lozf | iso-pub.ent | 2726 | Lozenge, filled |
| lvnE | iso-amsn.ent | 2268 | Less, vert, not double equals |
| nge | iso-amsn.ent | 2271 | Neither greater-than nor equal to |
| nle | iso-amsn.ent | 2270 | Not less-than-or-equal |
| npre | iso-amsn.ent | 22E0 | Not precedes, equals |
| nsce | iso-amsn.ent | 22E1 | Not succeeds, equals |
| nspar | iso-amsn.ent | 2226 | Not short parallel |
| pre | iso-amsr.ent | 227C | Precedes, equals |
| spar | iso-amsr.ent | 2225 | Short parallel |
| ssetmn | iso-amsb.ent | 2216 | Small set minus (reverse solidus) |
| star | iso-pub.ent | 22C6 | Star operator |
| starf | iso-pub.ent | 2605 | Black star |
| thkap | iso-amsr.ent | 2248 | Thick approximate |
| thksim | iso-amsr.ent | 223C | Thick similar |
| vsubne | iso-amsn.ent | 228A | Subset, not equals, variant |
| vsupnE | iso-amsn.ent | 228B | Subset not double equals, variant |
| vsupne | iso-amsn.ent | 228B | Superset, not equals, variant |
| xhArr | iso-amsa.ent | 2194 | Long left and right double arr |
| xharr | iso-amsa.ent | 2194 | Long left and right arr |
| xlArr | iso-amsa.ent | 21D0 | Long left double arrow |
| xrArr | iso-amsa.ent | 21D2 | Long right double arr |
| ssmile | iso-amsr.ent | 2323 | Small smile |
| sfrown | iso-amsr.ent | 2322 | Small frown |
Users needing alternate glyphs for these characters will have to rely on redefining them to use the private use area or other non-portable mechanisms to access them.
Named XML entities (except for the five predefined entities) cannot be used if they are not declared. Entity declaration requires either an external or an internal subset. Some classes of applications forbid the occurrence of markup declarations in documents. For these documents, named character entities are inaccessible.
In this section, we introduce an XML vocabulary with the semantics of character entity reference. This Standard defines the semantics of elements and attributes declared in the "http://www.oasis-open.org/docbook/xmlcharent/names" namespace.
This namespace contains exactly one element, char. The char element has two attributes, entity and name. They are mutually exclusive.
The entity attribute identifies characters by their character entity names. (The set of valid names is the closed set of names associated with character entity sets defined by this Standard.) Case is significant in entity names.
The name attribute identifies characters by their Unicode character names. (The set of valid names is the set of character names published in the [Unicode] specification, or any later version of that specification.) Case is insignificant in character names.
The [RELAX NG] definition of this namespace is shown in figure Figure 1.
Figure 1. The RELAX NG Definition of the http://www.oasis-open.org/docbook/xmlcharent/names Namespace
<?xml version="1.0"?>
<grammar xmlns="http://relaxng.org/ns/structure/0.9"
ns="http://www.oasis-open.org/docbook/xmlcharent/names">
<start>
<element name="char">
<choice>
<attribute name="entity">
<ref name="EntityNames"/>
</attribute>
<attribute name="name">
<ref name="UnicodeNames"/>
</attribute>
</choice>
</element>
</start>
<define name="EntityNames">
<!-- Logically, this is the list of ISO 9573 Character Entity Names -->
<!-- For now, just text. -->
<text/>
</define>
<define name="UnicodeNames">
<!-- Logically, this is the list of Unicode Character Names -->
<!-- For now, just text. -->
<text/>
</define>
</grammar>
Example 2 shows a sample document using this mechanism.
Example 2. Declaring and Using the ISO Latin 1 Character Entity Set
<doc xmlns:e="http://www.oasis-open.org/docbook/xmlcharent/names"> <p>This document uses the character names element to access character entities, such as "<e:char name="eacute"/>" and "<e:char name="COPYRIGHT SIGN"/>".</p> </doc>
The character names element is limited to contexts where elements may occur. In particular, elements may not occur in XML attribute values. Note, however, that internationalization requirements such as bidirectional language support and Ruby already require structure in arbitrary contexts. It is probably an error to use attributes for human-readable content.
A. Added Latin 1
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Added Latin 1//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isolat1.ent |
The following character entities are defined in this entity set:
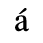
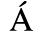
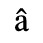
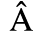
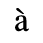
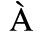
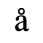
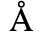
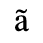
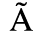
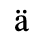
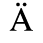
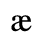
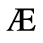
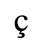
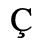
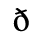
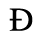
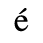
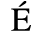
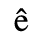
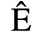
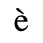
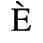
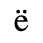
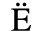
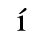
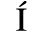

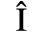
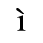
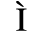
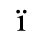
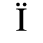
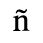
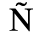
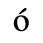
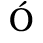
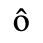
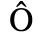
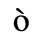
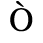
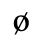
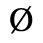
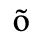
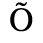
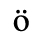
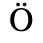
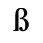
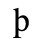
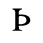
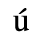
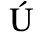
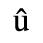
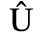
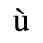
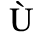
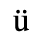
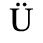
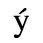
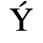
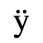
B. Added Latin 2
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Added Latin 2//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isolat2.ent |
The following character entities are defined in this entity set:
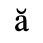
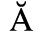
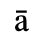
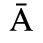
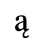
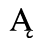
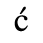
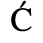
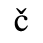
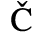
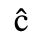
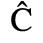
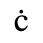
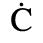
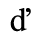
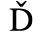
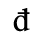
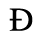
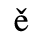
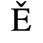
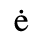
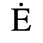
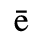
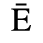
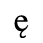
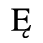
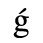
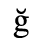
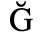
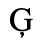
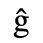
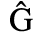
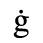
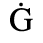
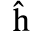
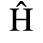
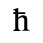
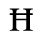
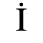
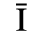
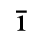
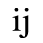

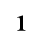
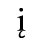
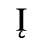
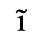
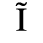
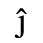

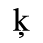
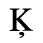
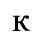
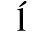
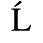
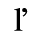
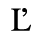
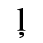
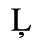
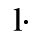
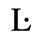
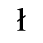
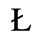
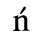
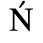
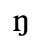
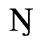
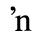
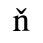
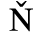
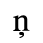
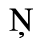
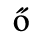
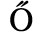
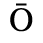
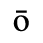
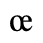
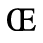
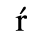
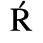
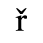
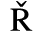
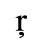
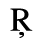
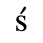
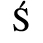
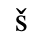
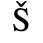
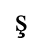
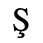
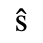
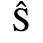
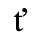
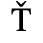
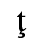
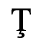
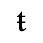
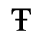
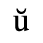
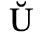
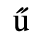
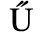
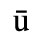
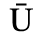
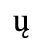
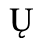
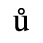
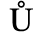
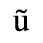
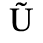

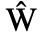
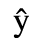
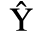
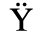
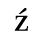
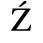
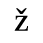
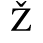
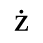
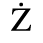
C. Greek Letters
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Greek Letters//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isogrk1.ent |
The following character entities are defined in this entity set:
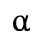
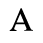
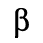
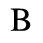
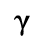
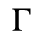
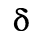

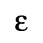
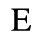
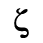
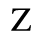
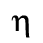
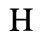
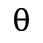

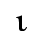
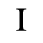
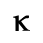
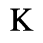
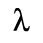
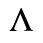
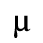
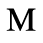
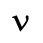
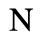
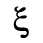

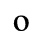
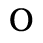

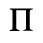
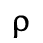
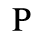
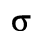
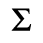
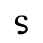
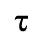
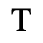
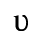
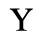
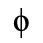
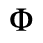
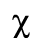
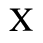
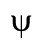
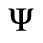

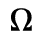
D. Monotoniko Greek
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Monotoniko Greek//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isogrk2.ent |
The following character entities are defined in this entity set:
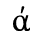
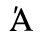
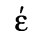
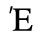
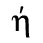
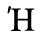
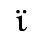
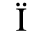
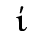
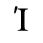
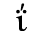
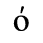
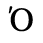
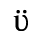
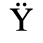
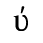
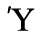
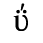

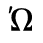
E. Russian Cyrillic
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Russian Cyrillic//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isocyr1.ent |
The following character entities are defined in this entity set:
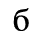
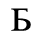
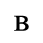
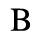
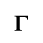
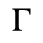
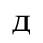
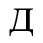
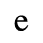
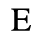
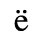
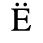
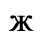


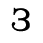
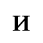
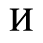
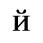
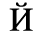
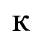
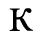
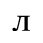
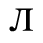
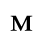
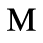
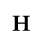
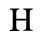
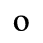
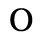
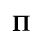
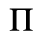
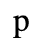
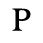
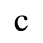
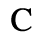
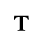
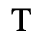
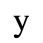
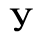
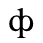
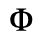
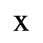
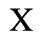
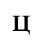
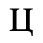
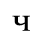
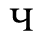
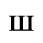
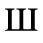
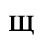
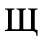
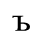
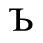
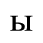
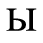
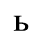
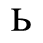
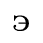
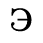
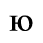
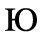
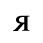
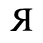
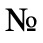
F. Non-Russian Cyrillic
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Non-Russian Cyrillic//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isocyr2.ent |
The following character entities are defined in this entity set:
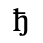
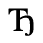
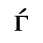
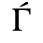
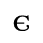
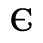
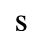
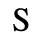
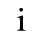
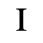
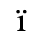
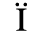
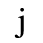
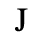
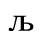
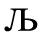
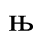
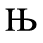
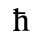
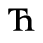
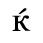
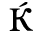
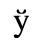
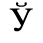
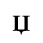
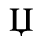
G. Numeric and Special Graphic
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Numeric and Special Graphic//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isonum.ent |
The following character entities are defined in this entity set:
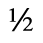
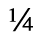
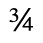
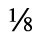
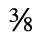
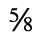
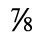
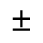
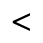
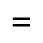
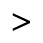
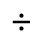

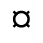
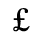
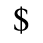
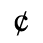
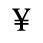
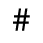
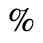
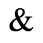

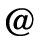
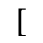
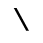
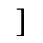
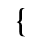

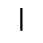
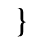
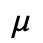
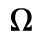

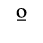
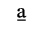
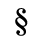
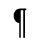







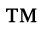
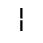
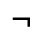


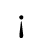
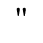

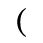
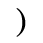
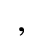
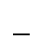


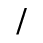

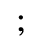

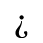

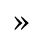

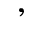


H. Diacritical Marks
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Diacritical Marks//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isodia.ent |
The following character entities are defined in this entity set:













I. Publishing
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Publishing//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isopub.ent |
The following character entities are defined in this entity set:




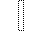

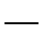
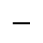




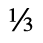
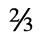
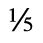
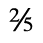
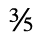
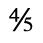
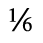
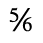
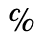























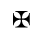



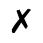

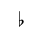



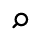

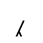
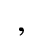
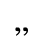
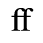
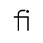
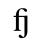
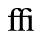
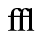
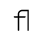









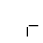
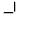
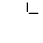
J. Box and Line Drawing
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Box and Line Drawing//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isobox.ent |
The following character entities are defined in this entity set:
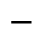
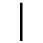
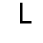
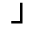
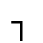
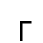
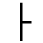
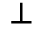
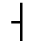
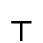
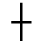
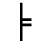
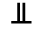
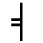

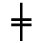
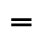

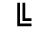
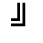
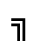

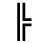
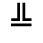
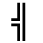

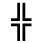
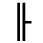
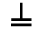
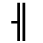
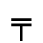

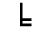
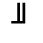
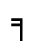
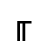
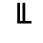
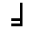
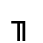
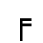
K. General Technical
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES General Technical//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isotech.ent |
The following character entities are defined in this entity set:
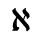

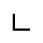

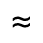

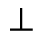
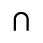
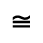
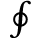
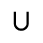
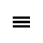
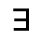

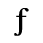



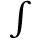
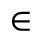
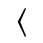
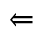
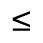
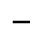
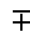

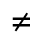
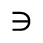


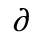
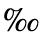
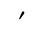
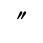
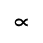

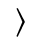

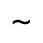
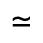
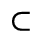
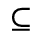
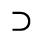
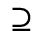


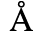
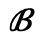

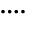
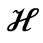
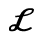

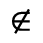
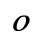
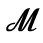
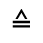
L. Greek Symbols
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Greek Symbols//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isogrk3.ent |
The following character entities are defined in this entity set:
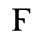
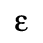
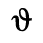
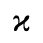

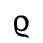
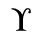
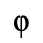
M. Alternative Greek Symbols
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Alternative Greek Symbols//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isogrk4.ent |
The following character entities are defined in this entity set:
N. Added Math Symbols: Ordinary
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Added Math Symbols: Ordinary//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isoamso.ent |
The following character entities are defined in this entity set:
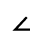
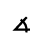
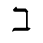

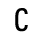
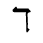
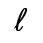
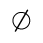
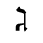
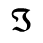
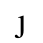
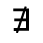

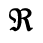
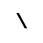
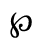
O. Added Math Symbols: Binary Operators
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Added Math Symbols: Binary Operators//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isoamsb.ent |
The following character entities are defined in this entity set:



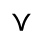



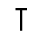












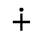
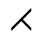



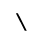
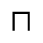
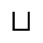

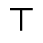
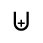
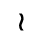



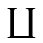
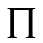
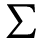
P. Added Math Symbols: Relations
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Added Math Symbols: Relations//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isoamsr.ent |
The following character entities are defined in this entity set:
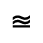

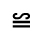
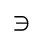


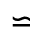
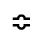
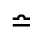

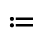
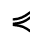

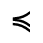
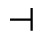

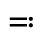
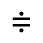
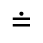
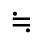
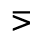
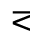
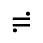
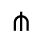

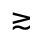

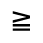
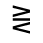
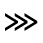
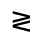
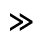
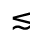

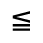
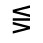
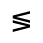



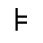
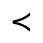
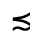

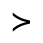
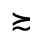
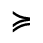
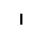

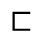
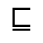
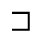
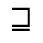

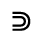
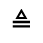

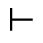
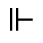
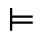
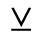


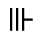
Q. Added Math Symbols: Negated Relations
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Added Math Symbols: Negated Relations//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isoamsn.ent |
The following character entities are defined in this entity set:
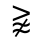
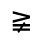
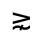
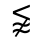
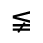
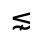
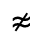
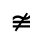
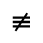
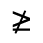
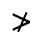
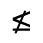
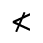

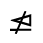
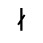
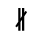
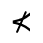
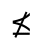


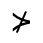
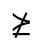
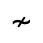
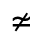
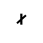
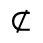
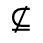
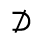
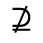
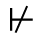
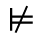
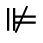
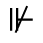
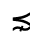
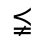
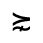
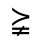
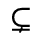
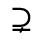
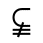
R. Added Math Symbols: Arrow Relations
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Added Math Symbols: Arrow Relations//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isoamsa.ent |
The following character entities are defined in this entity set:




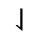
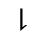
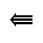
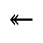
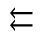
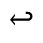
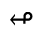


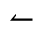

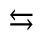
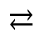

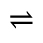
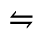
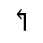



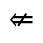
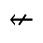

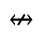
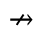
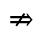

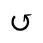
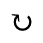


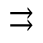
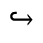
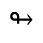
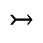
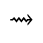
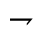
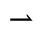
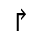


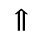
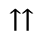
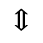

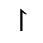
S. Added Math Symbols: Delimiters
Identifiers for this entity set:
| Public identifier: ISO 8879:1986//ENTITIES Added Math Symbols: Delimiters//EN//XML |
| System identifier: http://www.oasis-open.org/docbook/xmlcharent/0.2/isoamsc.ent |
The following character entities are defined in this entity set:
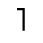
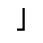
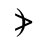
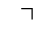

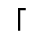
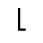
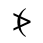
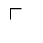
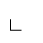
T. Unicode Glyphs
The Unicode reference glyphs in this document are examples only. Some characters have more than one Unicode representation and different Unicode characters may be appropriate in different contexts. The glyph images offer only one of many possible representations for the specified character.
Most of the glyphs this reference are from the TmsPF Roman font by Production First Software. A few glyphs are from Everson Mono.
Unicode support requires much more than a simple character to glyph mapping; for more information on Unicode, consult The Unicode Standard, Version 2.0 and Unicode Technical Report #8, which describes Unicode Version 2.1.
U. OASIS DocBook Technical Committee (Non-Normative)
Dennis Evans
Dick Hamilton
Nancy (Paisner) Harrison
Sabine Ocker
Michael Smith
Bob Stayton
Norman Walsh (Chair)
Normative
[ISO 8879:1986] JTC 1, SC 34. ISO 8879:1986 Information processing -- Text and office systems -- Standard Generalized Markup Language (SGML). 1986.
[XML 1.0] Tim Bray, Jean Paoli, C. M. Sperberg-McQueen, and Eve Maler, editors. Extensible Markup Language (XML) 1.0 Second Edition. World Wide Web Consortium, 2000.
[Namespaces] Tim Bray, Dave Hollander, and Andrew Layman, editors. Namespaces in XML. World Wide Web Consortium, 1999.
[RELAX NG] James Clark, editor. RELAX NG Specification (Committee Specification). OASIS. 2001.